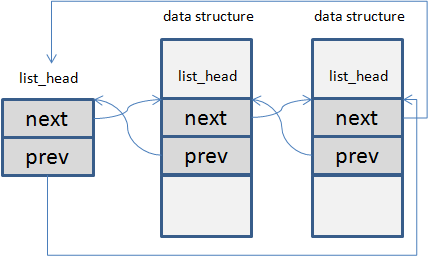
They are displayed in hex format as 8 bytes. The right most 4 bytes represent stardard signals, the left is Linux real-time signal extension. Each bit in the 8 bytes represents one corresponding signal. If the bits index starts from zero(the right most bit in the above), The corresponding signal is represented by bit[signalValue-1]. An example is that the signal SIGHUP, whose value is 1, is represented the bit 0.
Take the above SigBlk as example, the first two bytes are
0xfeff
The binary format is
1111,1110,1111,1111
It means all signals from 1 to 16 are blocked except the signal 9 (SIGKILL). This is true because SIGKILL cannot be blocked or ignored.
Last week, I did a small experiment of using oprofile to profile two piece of code. In this small experiment, I learned some basic ideas of using oprofile. In particular, I used oprofile to profile memory cache behaviour and the performance effect. In this experiment, I got ideas of how memory cache invalidation can affect the speed of running program. The following is the detail.
The Experiment Configuration
I ran the experiment in an Thinkpad T400 with a Ubuntu installation. The experiment needs to run on a multi-core processor because of profiling memory cache invalidation cost. In a single core processor, there is no such memory cache invalidation cost.
12345678910
$sudo lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 12.04 LTS
Release: 12.04
Codename: precise
$ cat /proc/cpuinfo |grep "model name"
model name : Intel(R) Core(TM)2 Duo CPU P8600 @ 2.40GHz
model name : Intel(R) Core(TM)2 Duo CPU P8600 @ 2.40GHz
Source Code
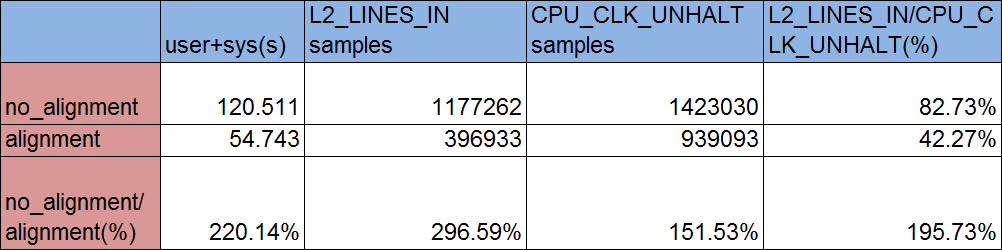
There are two pieces of programs, which are “no_alignment” and “alignment”. They are compiled with GNU GCC. Each program clones a child sharing the same memory address space, which means the parent and the child updating different fileds of the same global data. The difference is that the program “alignment” optimizing the fields of the shared_data to the cache line size alignment. In this way, the two fields are able to be fetched on different cache lines. Therefore, when the parent and the child runs on different cores, the “no_alignment” program has the cache invlidation costs between two cores, but the “alignment” program doesn’t.
The following are the source codes of the two programs. The only difference is the definition of struct shared_data.
#define _GNU_SOURCE#include <sched.h>#include <stdio.h>#include <errno.h>#include <stdlib.h>// shared datastructshared_data{unsignedintnum_proc1;unsignedintnum_proc2;};structshared_datashared;// define loops to run for a whileintloop_i=100000,loop_j=100000;intchild(void*);#define STACK_SIZE (8 * 1024)intmain(void){pid_tpid;inti,j;/* Stack */char*stack=(char*)malloc(STACK_SIZE);if(!stack){perror("malloc");exit(1);}printf("main: shared %p %p\n",&shared.num_proc1,&shared.num_proc2);/* clone a thread sharing memory space with the parent process */if((pid=clone(child,stack+STACK_SIZE,CLONE_VM,NULL))<0){perror("clone");exit(1);}for(i=0;i<loop_i;i++){for(j=0;j<loop_j;j++){shared.num_proc1++;}}}intchild(void*arg){inti,j;printf("child: shared %p %p\n",&shared.num_proc1,&shared.num_proc2);for(i=0;i<loop_i;i++){for(j=0;j<loop_j;j++){shared.num_proc2++;}}}
#define _GNU_SOURCE#include <sched.h>#include <stdio.h>#include <errno.h>#include <stdlib.h>// cache line size// hardware dependent value// it can checks from /proc/cpuinfo#define CACHE_LINE_SIZE 64// shared data aligned with cache line sizestructshared_data{unsignedint__attribute__((aligned(CACHE_LINE_SIZE)))num_proc1;unsignedint__attribute__((aligned(CACHE_LINE_SIZE)))num_proc2;};structshared_datashared;// define loops to run for a whileintloop_i=100000,loop_j=100000;intchild(void*);#define STACK_SIZE (8 * 1024)intmain(void){pid_tpid;inti,j;/* Stack */char*stack=(char*)malloc(STACK_SIZE);if(!stack){perror("malloc");exit(1);}printf("main: shared %p %p\n",&shared.num_proc1,&shared.num_proc2);/* clone a thread sharing memory space with the parent process */if((pid=clone(child,stack+STACK_SIZE,CLONE_VM,NULL))<0){perror("clone");exit(1);}for(i=0;i<loop_i;i++){for(j=0;j<loop_j;j++){shared.num_proc1++;}}}intchild(void*arg){inti,j;printf("child: shared %p %p\n",&shared.num_proc1,&shared.num_proc2);for(i=0;i<loop_i;i++){for(j=0;j<loop_j;j++){shared.num_proc2++;}}}
Testing
I was using the Oprofile 0.99 which has ‘operf’ program that allows non-root users to profile a specified individual process with less setup. Different CPUs have different supported events. The supported events, their meanings and accepted event format by operf can be checked from ophelp and the CPU’s hardware manual. In this experiment, the CLOCK event is CPU_CLK_UNHALTED and L2_LINES_IN is the number of allocated lines in L2 which is L2 cache missing number. As examples, the “CPU_CLK_UNHALTED:100000” tells operf to sample every 100000 unhalted clock with default mask(unhalted core cycles). The “L2_LINES_IN:100000:0xf0” tells operf to sample every 1000000 number of allocated lines in L2 on all cores with all prefetch inclusive.
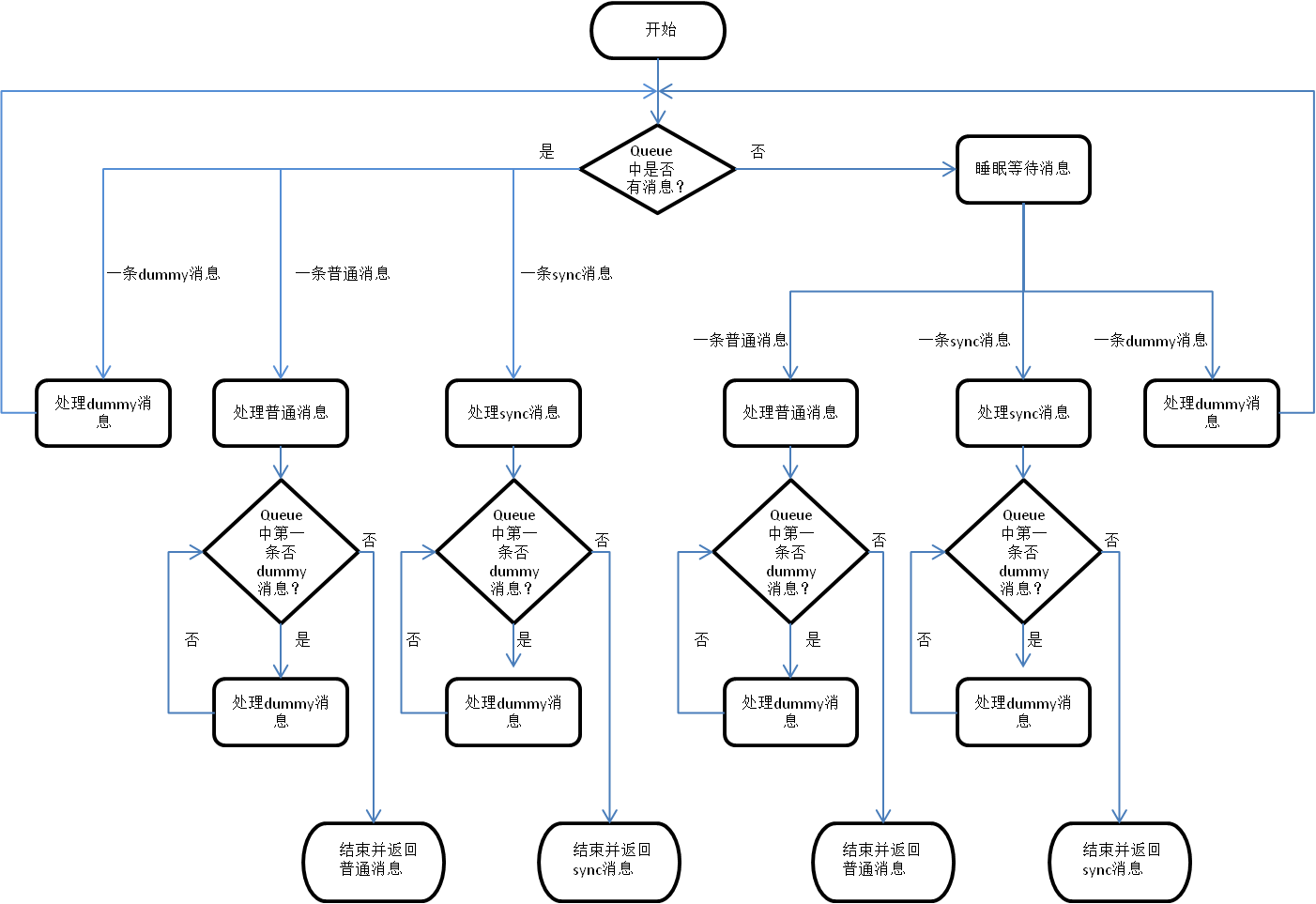
intmsg_recv_whole_msg(structmsg_client*client,structmsg_frag**head,intnonblock,structtimespec*ts){structmsg_frag*cur_msg;structmsg_queue*q;structext_wait_queuewait;structtimevaltv;intret=0;longtimeout=0;booldummy,peek_dummy,sleep_entry;boolfirst_entry=true;buffer_bottom_t*bb=NULL;*head=NULL;if(g_enable_timestamps)do_gettimeofday(&tv);rcu_read_lock();// make sure q is not freed (in RCU call back)q=client->q;if(unlikely(!q)){rcu_read_unlock();return-ENOTCONN;}prefetch(q);timeout=__prepare_timeout(ts);do{spin_lock_bh(&q->lock);if(likely(first_entry)){rcu_read_unlock();//we can unlock RCU because spin_lock_bh already disabled preemptfirst_entry=false;}else{/* Make sure next message is dummy because other threads may fetch it. */if(!__next_msg_is_dummy(q)&&((*head)!=NULL)){spin_unlock_bh(&q->lock);break;}}if(q->msg_queue_pending_msgs){sleep_entry=false;DTRACE(3,"msg_recv_whole_msg(): Msg priority queue not empty.\n");cur_msg=__get_first_msg(q,false);if(unlikely(cur_msg==NULL)){spin_unlock_bh(&q->lock);EPRINTF("Msg Q list empty while counter for msg is %u\n",q->msg_queue_pending_msgs);return-ERANGE;}dummy=MSG_IS_DUMMY_MSG(MSGHEADER(cur_msg));bb=(buffer_bottom_t*)(cur_msg->data);q->msg_queue_pending_msgs--;if(dummy){q->msg_queue_pending_dummy_msgs--;}if(need_input_sync(client,cur_msg)){client->q->msg_queue_pending_wosp_msgs--;}if(!MSG_IS_SYNC_MSG(bb)){q->msg_queue_size-=cur_msg->n_bufs;q->msg_queue_msgs--;msg_pid_queue_stat_dec(q,bb->process_id,cur_msg->n_bufs);}recv_input_sync_prepare(client,cur_msg);// must put behind sync msg send out, for sync msg will use filler2.if(!dummy){bb->filler2=(bb->filler2&0xffff0000)|get_and_inc_hand_seq(q,bb->process_id);}/* Take a peek whether the next message is a dummy message. */peek_dummy=__next_msg_is_dummy(q);spin_unlock_bh(&q->lock);recv_input_sync(client,cur_msg);ret=0;}else{cur_msg=NULL;dummy=peek_dummy=false;sleep_entry=true;if(unlikely(nonblock)){DPRINTF(3,"msg_recv_whole_msg(): nonblock, don't sleep\n");spin_unlock_bh(&q->lock);ret=-EAGAIN;}elseif(unlikely(timeout<0)){DPRINTF(3,"msg_recv_whole_msg(): timeout < 0: %ld\n",timeout);spin_unlock_bh(&q->lock);ret=-ETIMEDOUT;}else{wait.task=current;wait.state=STATE_NONE;DPRINTF(3,"msg_recv_whole_msg(): going to sleep.\n");ret=__wq_sleep(&client->q,&timeout,&wait);if(ret==0){cur_msg=wait.head;recv_input_sync(client,cur_msg);if(unlikely(MSG_IS_DUMMY_MSG(MSGHEADER(cur_msg)))){WPRINTF("Unexpected dummy message received in wait task. From %x.%x.\n",MSGHEADER(cur_msg)->computer,MSGHEADER(cur_msg)->family);dummy=true;}}}}DTRACE(3,"msg_recv_whole_msg() ret: %d, msg:(%p)\n",ret,cur_msg);if(dummy)msg_free_msg(&cur_msg);elseif((*head)==NULL)//Store the non-dummy message to receiver*head=cur_msg;}while(((*head==NULL)&&!sleep_entry)||(dummy&&sleep_entry)||unlikely(peek_dummy));/* restore bb->phys_computer because all input-sync related logic is completed here restore it so that monitor tools sees compliant data as cIPA */if(*head){bb=(buffer_bottom_t*)(*head)->data;bb->phys_computer=bb->next_phys_computer;if(g_enable_timestamps){set_time_rec(*head,TIMEREC_ENTER_IOCTL,&tv);}}__msg_monitor(*head,MON_POINTS_T_RECEIVE_C);returnret;}
/** * Aquire the q's lock need RCU read lock proctect because the q can be release * in the mid without that proctect. After the q's lock is got, rcu read lock * is released because q cannot be released anymore * * return NULL: failure * Otherwise: pointer to q is returned and q is locked */STATICINLINEstructmsg_queue*client_q_lock_protect(structmsg_client*client){structmsg_queue*q=NULL;rcu_read_lock();q=client->q;if(unlikely(!q)){rcu_read_unlock();returnNULL;}spin_lock_bh(&q->lock);rcu_read_unlock();returnq;}#define client_q_unlock(q) spin_unlock_bh(&q->lock)/** * Get message from pending queue. * * Caller should hold the q's lock and the q shouldn't be empty * * The q's lock will be freed in this function when it returns * * Return: 0 is successful otherwise failure * Output: In case of success, *head helds the pointer of the received msg */STATICINLINEint__get_a_msg_from_q(structmsg_client*client,structmsg_frag**head){booldummy;buffer_bottom_t*bb=NULL;structmsg_queue*q=client->q;structmsg_frag*cur_msg=NULL;cur_msg=__get_first_msg(q,false);if(unlikely(!cur_msg)){EPRINTF("Msg Q list empty while counter for msg is %u\n",q->msg_queue_pending_msgs);client_q_unlock(q);return-ERANGE;}q->msg_queue_pending_msgs--;dummy=MSG_IS_DUMMY_MSG(MSGHEADER(cur_msg));if(dummy){q->msg_queue_pending_dummy_msgs--;}if(need_input_sync(client,cur_msg)){client->q->msg_queue_pending_wosp_msgs--;}bb=(buffer_bottom_t*)(cur_msg)->data;if(!MSG_IS_SYNC_MSG(bb)){q->msg_queue_size-=cur_msg->n_bufs;q->msg_queue_msgs--;msg_pid_queue_stat_dec(q,bb->process_id,cur_msg->n_bufs);}recv_input_sync_prepare(client,cur_msg);// must put behind sync msg send out, for sync msg will use filler2.if(!dummy){bb->filler2=(bb->filler2&0xffff0000)|get_and_inc_hand_seq(q,bb->process_id);}client_q_unlock(q);*head=cur_msg;return0;}/** * Waiting for new message, it will sleep while no message is arrival. * Caller should hold the q's lock * The __wq_sleep will free the q's lock when it returns from. */STATICINLINEint__waiting_for_new_msg(structmsg_queue*q,intnonblock,structtimespec*ts,structmsg_frag**head){intret=0;longtimeout=0;structext_wait_queuewait;*head=NULL;timeout=__prepare_timeout(ts);if(unlikely(nonblock)){DPRINTF(3,"%s(): nonblock, don't sleep\n",__func__);spin_unlock_bh(&q->lock);ret=-EAGAIN;}elseif(unlikely(timeout<0)){DPRINTF(3,"%s(): timeout < 0: %ld\n",__func__,timeout);spin_unlock_bh(&q->lock);ret=-ETIMEDOUT;}else{wait.task=current;wait.state=STATE_NONE;DPRINTF(3,"%s(): going to sleep.\n",__func__);ret=__wq_sleep(&q,&timeout,&wait);if(ret==0){*head=wait.head;}}returnret;}/** * return 0 until it received a non dummy message, the recevied msg is saved * in the parameter cur_msg. If it received a dummy message, it handles * this dummy message and back to receive next message again * * return non-zero if there are errors */STATICINLINEintmsg_recv_a_nondummy_msg(structmsg_client*client,structmsg_frag*cur_msg,intnonblock,structtimespec*ts){booldummy=false;// the received msg is a dummy messageintret=0;structmsg_queue*q;cur_msg=NULL;do{/* Get first un-dummy messages. */q=client_q_lock_protect(client);if(unlikely(!q)){return-ENOTCONN;}if(q->msg_queue_pending_msgs){DTRACE(3,"%s(): Msg priority queue NOT empty.\n",__func__);ret=__get_a_msg_from_q(client,&cur_msg);}else{DTRACE(3,"%s(): Msg priority queue empty.\n",__func__);ret=__waiting_for_new_msg(q,nonblock,ts,&cur_msg);}if(unlikely(ret!=0)){returnret;}recv_input_sync(client,cur_msg);dummy=MSG_IS_DUMMY_MSG(MSGHEADER(cur_msg));if(dummy){msg_free_msg(&cur_msg);}}while(dummy);// a non dummy message is received, return OKreturn0;}/** * exhaust all dummy messages in the queue until the queue is empty or the head * message isn't a dummy message. * * Up to now, no need to know whether this function succeeds or not. Therefore, * no error code is returned even if there are errors */STATICINLINEvoidexhaust_dummy_msgs_from_queue(structmsg_client*client){structmsg_queue*q;structmsg_frag*cur_msg=0;for(;;){q=client_q_lock_protect(client);if(unlikely(!q)){break;}if(!__next_msg_is_dummy(q)){client_q_unlock(q);break;}if(unlikely(__get_a_msg_from_q(client,&cur_msg))){break;}msg_free_msg(&cur_msg);}}/* * */intmsg_recv_whole_msg(structmsg_client*client,structmsg_frag**head,intnonblock,structtimespec*ts){intret=0;structtimevaltv;buffer_bottom_t*bb=NULL;structmsg_frag*cur_msg=0;*head=NULL;if(g_enable_timestamps)do_gettimeofday(&tv);ret=msg_recv_a_nondummy_msg(client,cur_msg,nonblock,ts);if(unlikely(!ret)){returnret;}/* restore bb->phys_computer because all input-sync related logic is completed here * restore it so that monitor tools sees compliant data as cIPA */*head=cur_msg;cur_msg=NULL;bb=(buffer_bottom_t*)(*head)->data;bb->phys_computer=bb->next_phys_computer;if(g_enable_timestamps){set_time_rec(*head,TIMEREC_ENTER_IOCTL,&tv);}/* exhaust dummy msgs before give the received msg to user * for better latency of relative messages */exhaust_dummy_msgs_from_queue(client);returnret;}